
Diese Masterarbeit beschäftigt sich mit der Clusteranalyse von strukturierten aber komplexen Produktdaten, wie sie in typischen Product-Information-Management-Systemen vorkommen. Es wird ein neuartiges hierarchisches Top-down-Clustering-Verfahren vorgestellt – der Bisecting K-Prototypes. Dieses Verfahren ist in der Lage, mit gemischten Datensets (numerische und kategorische Daten) umzugehen, ohne vorher vielfältige Transformationen und Veränderungen der Daten vorauszusetzen. Bspw. geht das Verfahren problemlos mit einer hohen Menge an fehlenden Werten ("null"-Values) um. Außerdem wird eine Methode zur Verarbeitung sog. Mehrfach-Selects als multi-kategorische Attribute vorgestellt, um die Anzahl an verarbeitbaren Attributen weiter zu erhöhen. Diese Form der Verarbeitung kann auch auf String-Attribute mit hoher Varianz angewandt werden. Im anschließenden Praxisteil wurde ein Datenset mit Smartphones und Smartphone-Hüllen zusammengestellt, das beschriebene Clustering-Verfahren implementiert und auf das Datenset angewendet. Die Evaluation der Ergebnisse zeigt, dass sinnvolle Cluster von diesem Verfahren gebildet werden können. Besonders das Clustering mit ausschließlich numerischen und kategorischen Daten bildet die besten Cluster. Die hergeleitete Verarbeitung multi-kategorischer Werte zeigte kaum einen positiven Einfluss auf das Clustering. Beim Clustern mit den String-Attributen allein konnten mit diesem Verfahren allerdings wiederum adäquate Cluster gefunden werden, sodass sich aus dieser Art der Verarbeitung in Zukunft interessante Anwendungen ergeben könnten.
Generisches Clustern hochkomplexer Produktdaten
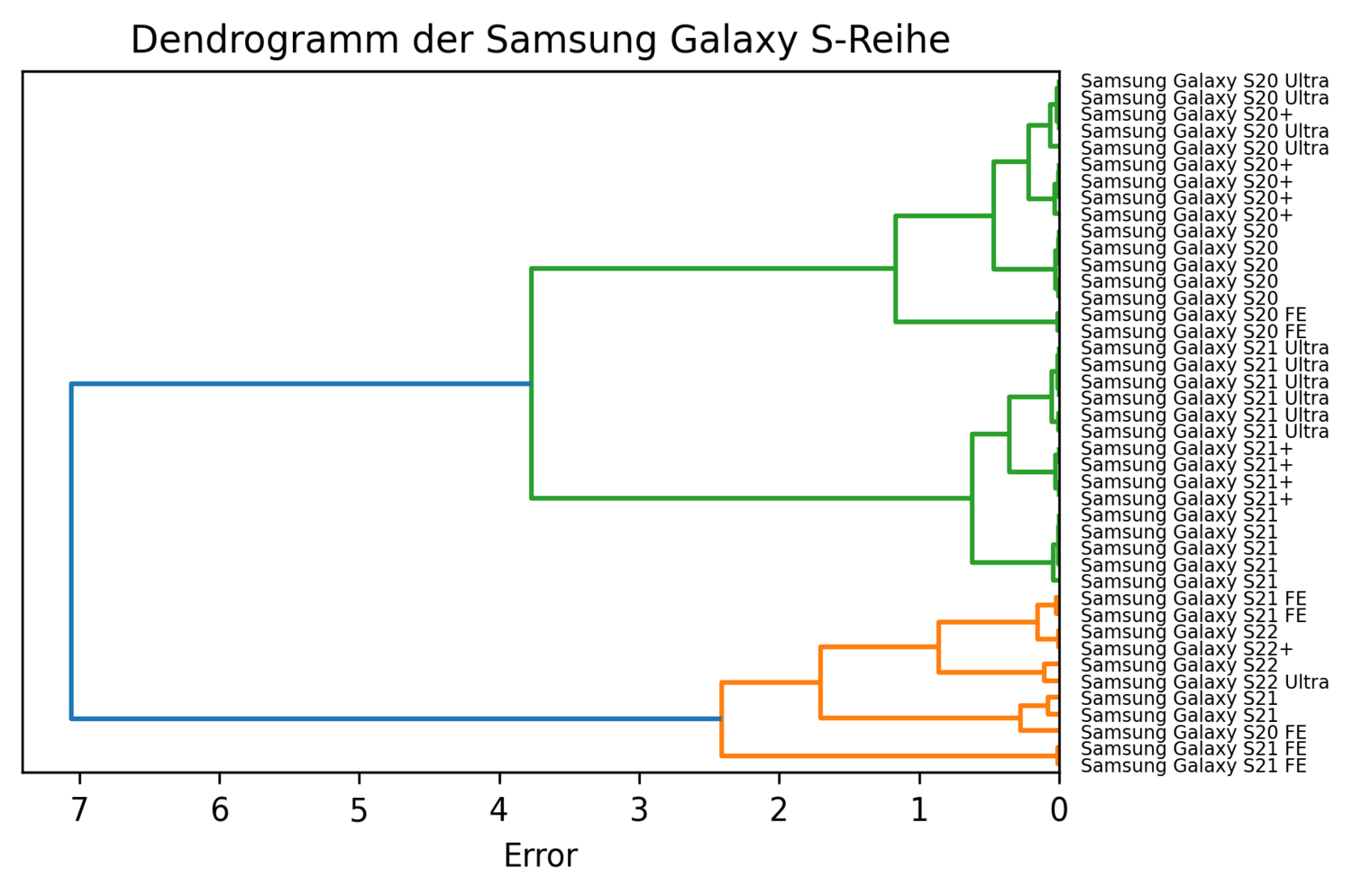
Ergebnis des Clustering der Smartphones mit nur numerischen und kategorischen Attributen
This master thesis is about cluster analysis of structured and complex product data as they appear frequently in typical Product Information Management Systems. A new hierarchical divisive clustering algorithm – Bisecting K-Prototypes – is introduced. This algorithm clusters mixed datasets (numerical and categorical) without the need for extensive data preparation. E.g. it is also able to cope with missing values in the dataset without handling these first. Additionally, a method for working with multi-select data (multi-categorical) is developed to further extend the number of attributes the algorithm can consider for clustering. This method can be used for string data with high variance as well. Afterwards, a practical evaluation followed. A dataset with smartphones and smartphone cases was created. The clustering algorithm was implemented and used to cluster the dataset. The results indicate, that the algorithm does produce meaningful clusters. Especially the usage of only numerical and categorical values yields the best outcomes. The proposed method for multi-categorical data however does not improve the results. On the other hand, using the said method when clustering string values produces somewhat acceptable clusters. This might provide interesting approaches to the clustering of such datasets in the future.